5 Principles that Should Underpin Meta’s Search for a Network Quality Metric
May 30, 2022

Network Quality is much trickier than one might think. Networks consist of layers of technologies that, ironically, can’t communicate with each other and are optimized with self-centered motivation. The Metaverse, or any massive interactive AR/VR will have unprecedented network quality requirements and the communication industry and Metaverse infrastructure developers are in for a challenge.
I’ve already written a blog on the challenges of delivering a Metaverse over the internet, and I wrote a chapter on the difficulties of Network Quality for Meta supported Telecom Infra Project. In Meta’s latest blog at MWC, Meta shows their recognition of the challenges at hand and asks for industry-wide collaboration. Awesome!
This blog goes through five principles that a network quality framework needs to help networks deliver the Metaverse.
Let's start with two great quotes from Metas press release, before I try to bullet point the issues.
“In today’s networks, the protocols and algorithms operating at the application layer — such as adaptive bit rate control loops for streaming video — do not have access to metrics on link quality and congestion from the physical layer.” … “We believe there’s an opportunity to realize significant gains by moving past this kind of siloed optimization and toward open interfaces for sharing metrics between OSI layers as well as network domains.”
"As we collaborate with the industry, there is also a need to define a common framework of how to measure and evaluate readiness for metaverse use cases of different levels of intensity. For example, in order to align on an industry-wide definition of a highly capable end-to-end network, we need to develop common quality of experience metrics and the role they play in evaluating network capabilities, and correlate the relationship between network quality of service metrics with user quality of experience metrics."
The main requirements
Unpacking these quotes and the larger article, let's try to formalize what Meta is looking for. Based on the language, they are looking for a Network Quality Metric for the future internet that is:
Independent of OSI Layer and Network Technology
From “moving past this kind of siloed optimization and toward open interfaces for sharing metrics between OSI layers as well as network domains”
Translatable from complex raw data into something actionable and relatable for users
From “correlate the relationship between network quality of service metrics with user quality of experience metrics."
Let's add one more
Now, I would like to add an additional requirement that will make the life of everyone involved a whole lot easier, and it will be key to doing useful things across the existing silos.
Make 1+1=2 and 2-1=1.
I am guessing this needs some explanation. Surely this is not revolutionary?
1+1=2
Most Network Quality Metrics, like the Mbps on a Speedtest, are inherently End-to-End, between two arbitrary points (from a holistic network point of view). From your device to some server, passing network equipment along the way. However, if you have a speedtest from a->b->c and one from c->d->e and want to know the speed from a->b, from b->c, from c->d, and d->e there is no mathematically sensible way of calculating it!* In this case, 1+1 does not equal 2.
It thus follows that if 1+1≠2 then there is no point in “sharing metrics between OSI layers as well as network domains”. So what can one do about it?
2-1=1
The goal of sharing metrics between OSI Layers and network domains must be to improve our ability to optimize, troubleshoot and understand networks. Imagine you got an E2E network test with 100 ms latency, and you knew that it traveled through network Domain A and B. If you also had the information that Network Domain B had between 1-20 ms latency, you could deduce that 80-99ms of the latency came from Domain A.
If your network quality metric can do this, you are much, much closer to troubleshooting and understanding the network.
NOTE: + and - are essential for the actionability
of a network quality metrics/requirements
Summarizing the requirements
Let me try to summarize the requirements with an analogy from the world of medical diagnostics.
A doctor translates complex data into something relatable, like:
Sick and what disease?
Healthy
Healthy enough to run a marathon
What actions you can perform to improve it:
Exercise,
Sleep
Medication
Details about your blood-pressure, hormone levels, blood levels (raw-data) ,etc, etc. are not immediately visible but remain accessible in your Electronic Medical Record.
It must be clear that the goal is not to ignore the details, but to simplify the diagnosis to a relatable and actionable level for many levels of medical knowledge. The doctor translates complex health requirements into relatable, actionable statements for the patient. This seems like a good role model for a network quality metric.
Now, how do we get there?
Five Principles
Let's look at what a network quality metric needs to fulfill Meta’s (and my) goal.
Principle 1: It begins (and ends) with Latency
To capture network quality sufficiently, the consensus is moving towards latency as the primary measure. Any lack of bandwidth manifests itself as latency, and packet loss can be seen as infinite latency, so all dimensions can be covered under the latency umbrella.
Latency also has the advantage of being independent of network technology and layers.
Principle 2: Ask not what the network gives. Ask what it takes away
We need to understand how much latency a network segment adds to the total latency. Why? Remember the importance of 1+1 and 2-1? These things get very tricky, very quickly with speedtests. How do you add 200 Mbps and 100 Mbps?.
It is much easier, mathematically, to model the network in terms of how much latency each network segment adds. This concept is called Quality Attention, and is key for 1+1 (composability) and 2-1 (decomposability). To oversimplify, if each network segment adds 5ms of latency, and you send traffic over 5 segments, it takes 25 ms. Easy peasy.
Latency measures can come from a range of sources. One can monitor real traffic or send probes. There are many ways of probing, and the real traffic inherently goes to different servers that reside in different parts of the internet. Real traffic and probes may be treated differently. It is all a bit of a mess. This mess is another reason why composability is so important. When we have a composable and decomposable network quality metric, a sample from b→c adds useful information to a sample through a->b->c->d. Knowing your neighbor's speedtest results gives you no useful information. Knowing how much latency his network adds at different segments does!
A quick example, if the end user experience is poor and we know something specific about, say, the WiFi, we can use that information to say something about the rest of the network. When using the quality attenuation principle, every piece of information about the network is useful. This lets us find the source of degradation. Speedtests and Mbps do not work this way.
If Meta used their scale deployments to crowdsource measurements, it would be near pointless if their metrics did not support composability and decomposability.
Principle 3: The worst 1-2% is key (but you can’t ignore the average)
Latency is the key. But how do you measure and aggregate statistics? Average latency and jitter have been the flavor for some time, but we are seeing that the 98th and 99th percentile matters more than both [bitag], but only for some use cases (interactive applications like video conferencing / gaming etc.). So, we need the 98th and 99th percentile AND the average or median.
Of course, the ideal would be to store every sample, but that would require way too much data/network/memory to be useful. We need to look for a compromise. Something like: 1st,50th,70th,80th,90th,95th,98th, 99th,99.5th,99.9th100th percentiles for a certain period of time (like a minute).
An advantage of this approach is that we can use some clever statistical techniques to go from these percentiles to approximate a distribution. And distributions are what? You guessed it, they’re composable! Statistics give us the tools to calculate 1+1 with distributions. Average latency and jitter do not.
Principle 4: We must know if we are getting there in time
Any Application performance over a network can be specified through one or more latency requirements. This is, once again, because insufficient bandwidth manifests as latency, and packet loss is just infinite latency.
Applications can formulate their requirements in a format such as: I need 90% of packets to arrive within 100ms and 100% to arrive within 200ms. The avid reader will have noticed that this is the same format as we can store latency statistics. If we set a requirement for 100ms on the 90th percentile and 200ms for the 100th percentile, we can compare measurements and application requirements directly. Or, as Meta puts it: “correlate the relationship between network quality of service metrics with user quality of experience metrics.
Now that we have a robust method for determining if the network is good enough, we should go from the correlation, back to our medical diagnosis example, to provide relatable statements for the end user. By also having application developers (or SLA makers) formulate a “beyond this point, my application has 0% chance of being functional”. We can get somewhere.
By having applications formulating this, we have:
If the network quality is X or better, the application will work perfectly
If the network quality is below Y, the application will not work at all
The mathematical Distance between the two
The 3rd point is crucial, because internet experience is not binary (it works or it doesn't). There is plenty of nuance in between. Having a distance measure gives us the ability to normalize and make statements like:
“Application X (e.g., Zoom) has a 75% chance of working perfectly on this network”, which is pretty relatable.
Principle 5: We need to be able to figure out the cause of degradation
When dealing with latency as a network quality metric, one difficulty is that latency may have several sources. Let’s remind ourselves of some cor e principles. To make a network quality metric actionable, we need ways of separating the causes: To figure out how to fix something, we first need to know what is broken.
There are 3 main causes of latency:
Physical Travel Time, which is governed by the speed of light and network technologies
Serialization, which is the processing time of packets
Queuing, which is caused by competition with other traffic.
However, #2 above is becoming negligible in a modern network, and certainly for any network capable of a metaverse-esque application. So, we are down to Travel Time and Queuing. When observing a network segment over time, we can with simple statistics separate the latency from each cause when using the concept of Quality Attenuation.
Summary
We need a network quality metric that can translate complex network statistics into relatable and actionable statements and be decoupled from network technology and layer.
The network quality metric must be a latency distribution as it is independent of network technology and layer, and lets us compose and decompose network segments and separate root causes which is key for actionability. A latency distribution lets us use common statistical tools, which is necessary as we cannot capture all data about a network, and we have to work in the realm of probabilities.
To make the metric translatable to relatable statements about experiences, the framework needs to let applications or other QoS requirements speak the same language. It has to be something similar to a latency distribution, and use this to translate the network quality into probabilistic statements about application’s performance. E.g., Zoom has a 97% chance of a perfect experience across this network
Luckily, all of this is covered by Broadband Forums standard QED (TR.452)
Appendix 0 - Comparing with other Frameworks:
Comparing with other network quality frameworks:
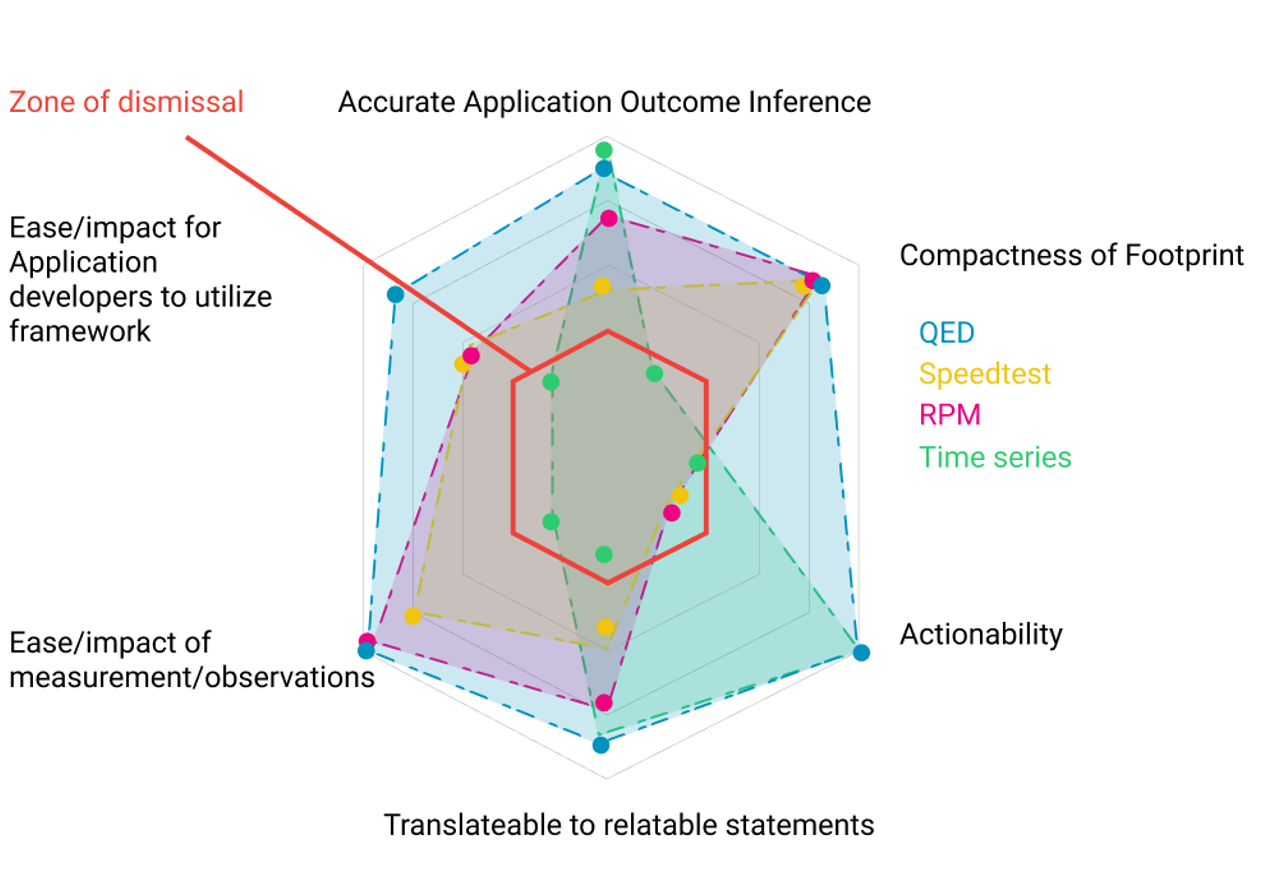
Appendix 1 - Typical Criticism:
Justification for Quantitative Timeliness Agreements (QTA) as QoS Requirements framework
First, let me succinctly describe my goal: A framework, that with a minimal amount of data and overhead, can translate Applications Network Requirements and any Networks Performance to objective and relatable Application Performance Statements.
Now, QED and QTAs answer my goal. Let me explain how.
We can describe an Applications Network Requirements (APR) as a list of latency requirement percentiles: For example: “Zoom needs: 90% of packets needs to arrive within 100ms, 99% within 200ms, and 100% within 250ms.” and: “Beyond 100 area outside the QTA, there is no chance of the application working”
A latency distribution can be captured and approximated on any network with a range of different techniques.
We can map the APR and the empirically measured latency distribution. If there is a breach we have a mathematical distance between “No chance of working” and “will work perfectly”. We can normalize this into a probability measure.
We have a one-dimensional measure for between perfect and useless. Which makes optimization much easier and the measure easier to understand
For example, it would generate a statement like: “On this network, Zoom has a 94% probability of perfection”
All in all, it requires minimal data, is objective, and can capture a wide range of application requirements and translate it to relatable statements.
Typical Criticism:
Missing Temporal Information in Distributions
A latency series of:
1,20,1,20,1,20,1,20,1,20
and
1,1,1,1,1,20,20,20,20,20
Will have identical distributions, but may have different application performance. We are getting into the tradeoff between ease. I.e. The QTA framework cannot capture all varieties of application outcome.
My answer to this is twofold:
First, we cannot capture latency on every packet that is sent. We can probe and sample, but there will always be unknowns. We are now in the realm of probability. Perfection is impossible, but instead of denying this, I think we should embrace it, which is why I think talking about the probability of outcomes is the way forward. A huge advantage of the QTA framework is having a single distance measure between perfect and useless as it lets us approximate probabilities in between. I do not see how we can create a single distance measure if we add a temporal dimension as well. Another dimension brings us back to (one of the) problems with Mbps, Average Latency, Jitter, and Packet Loss or the challenge of having multiple dimensions of network quality to deal with.
My second point is that adding temporal information still does not guarantee perfection. You could add something like a Pairwise Distance (PWD) measure:
1,20,1,20,1,20,1,20,1,20 ~PWD = 19+19+19+19+19+19 = 171
and
1,1,1,1,1,20,20,20,20,20 ~0+0+0+0+0+19+0+0+0+0+0 = 19
Which would capture the difference.
My aversion to this is that it starts to become very difficult to describe the requirements. Also, because there are many different ways we can get to the same PWD, and there is no guarantee that an identical PWD will have identical application outcomes. It seems to me to add more problems than it solves.
To Conclude, while the assumption of linear relationship between quality and the distance measure will be incorrect many cases, it seems that there is no other feasible solution.
Network Quality is much trickier than one might think. Networks consist of layers of technologies that, ironically, can’t communicate with each other and are optimized with self-centered motivation. The Metaverse, or any massive interactive AR/VR will have unprecedented network quality requirements and the communication industry and Metaverse infrastructure developers are in for a challenge.
I’ve already written a blog on the challenges of delivering a Metaverse over the internet, and I wrote a chapter on the difficulties of Network Quality for Meta supported Telecom Infra Project. In Meta’s latest blog at MWC, Meta shows their recognition of the challenges at hand and asks for industry-wide collaboration. Awesome!
This blog goes through five principles that a network quality framework needs to help networks deliver the Metaverse.
Let's start with two great quotes from Metas press release, before I try to bullet point the issues.
“In today’s networks, the protocols and algorithms operating at the application layer — such as adaptive bit rate control loops for streaming video — do not have access to metrics on link quality and congestion from the physical layer.” … “We believe there’s an opportunity to realize significant gains by moving past this kind of siloed optimization and toward open interfaces for sharing metrics between OSI layers as well as network domains.”
"As we collaborate with the industry, there is also a need to define a common framework of how to measure and evaluate readiness for metaverse use cases of different levels of intensity. For example, in order to align on an industry-wide definition of a highly capable end-to-end network, we need to develop common quality of experience metrics and the role they play in evaluating network capabilities, and correlate the relationship between network quality of service metrics with user quality of experience metrics."
The main requirements
Unpacking these quotes and the larger article, let's try to formalize what Meta is looking for. Based on the language, they are looking for a Network Quality Metric for the future internet that is:
Independent of OSI Layer and Network Technology
From “moving past this kind of siloed optimization and toward open interfaces for sharing metrics between OSI layers as well as network domains”
Translatable from complex raw data into something actionable and relatable for users
From “correlate the relationship between network quality of service metrics with user quality of experience metrics."
Let's add one more
Now, I would like to add an additional requirement that will make the life of everyone involved a whole lot easier, and it will be key to doing useful things across the existing silos.
Make 1+1=2 and 2-1=1.
I am guessing this needs some explanation. Surely this is not revolutionary?
1+1=2
Most Network Quality Metrics, like the Mbps on a Speedtest, are inherently End-to-End, between two arbitrary points (from a holistic network point of view). From your device to some server, passing network equipment along the way. However, if you have a speedtest from a->b->c and one from c->d->e and want to know the speed from a->b, from b->c, from c->d, and d->e there is no mathematically sensible way of calculating it!* In this case, 1+1 does not equal 2.
It thus follows that if 1+1≠2 then there is no point in “sharing metrics between OSI layers as well as network domains”. So what can one do about it?
2-1=1
The goal of sharing metrics between OSI Layers and network domains must be to improve our ability to optimize, troubleshoot and understand networks. Imagine you got an E2E network test with 100 ms latency, and you knew that it traveled through network Domain A and B. If you also had the information that Network Domain B had between 1-20 ms latency, you could deduce that 80-99ms of the latency came from Domain A.
If your network quality metric can do this, you are much, much closer to troubleshooting and understanding the network.
NOTE: + and - are essential for the actionability
of a network quality metrics/requirements
Summarizing the requirements
Let me try to summarize the requirements with an analogy from the world of medical diagnostics.
A doctor translates complex data into something relatable, like:
Sick and what disease?
Healthy
Healthy enough to run a marathon
What actions you can perform to improve it:
Exercise,
Sleep
Medication
Details about your blood-pressure, hormone levels, blood levels (raw-data) ,etc, etc. are not immediately visible but remain accessible in your Electronic Medical Record.
It must be clear that the goal is not to ignore the details, but to simplify the diagnosis to a relatable and actionable level for many levels of medical knowledge. The doctor translates complex health requirements into relatable, actionable statements for the patient. This seems like a good role model for a network quality metric.
Now, how do we get there?
Five Principles
Let's look at what a network quality metric needs to fulfill Meta’s (and my) goal.
Principle 1: It begins (and ends) with Latency
To capture network quality sufficiently, the consensus is moving towards latency as the primary measure. Any lack of bandwidth manifests itself as latency, and packet loss can be seen as infinite latency, so all dimensions can be covered under the latency umbrella.
Latency also has the advantage of being independent of network technology and layers.
Principle 2: Ask not what the network gives. Ask what it takes away
We need to understand how much latency a network segment adds to the total latency. Why? Remember the importance of 1+1 and 2-1? These things get very tricky, very quickly with speedtests. How do you add 200 Mbps and 100 Mbps?.
It is much easier, mathematically, to model the network in terms of how much latency each network segment adds. This concept is called Quality Attention, and is key for 1+1 (composability) and 2-1 (decomposability). To oversimplify, if each network segment adds 5ms of latency, and you send traffic over 5 segments, it takes 25 ms. Easy peasy.
Latency measures can come from a range of sources. One can monitor real traffic or send probes. There are many ways of probing, and the real traffic inherently goes to different servers that reside in different parts of the internet. Real traffic and probes may be treated differently. It is all a bit of a mess. This mess is another reason why composability is so important. When we have a composable and decomposable network quality metric, a sample from b→c adds useful information to a sample through a->b->c->d. Knowing your neighbor's speedtest results gives you no useful information. Knowing how much latency his network adds at different segments does!
A quick example, if the end user experience is poor and we know something specific about, say, the WiFi, we can use that information to say something about the rest of the network. When using the quality attenuation principle, every piece of information about the network is useful. This lets us find the source of degradation. Speedtests and Mbps do not work this way.
If Meta used their scale deployments to crowdsource measurements, it would be near pointless if their metrics did not support composability and decomposability.
Principle 3: The worst 1-2% is key (but you can’t ignore the average)
Latency is the key. But how do you measure and aggregate statistics? Average latency and jitter have been the flavor for some time, but we are seeing that the 98th and 99th percentile matters more than both [bitag], but only for some use cases (interactive applications like video conferencing / gaming etc.). So, we need the 98th and 99th percentile AND the average or median.
Of course, the ideal would be to store every sample, but that would require way too much data/network/memory to be useful. We need to look for a compromise. Something like: 1st,50th,70th,80th,90th,95th,98th, 99th,99.5th,99.9th100th percentiles for a certain period of time (like a minute).
An advantage of this approach is that we can use some clever statistical techniques to go from these percentiles to approximate a distribution. And distributions are what? You guessed it, they’re composable! Statistics give us the tools to calculate 1+1 with distributions. Average latency and jitter do not.
Principle 4: We must know if we are getting there in time
Any Application performance over a network can be specified through one or more latency requirements. This is, once again, because insufficient bandwidth manifests as latency, and packet loss is just infinite latency.
Applications can formulate their requirements in a format such as: I need 90% of packets to arrive within 100ms and 100% to arrive within 200ms. The avid reader will have noticed that this is the same format as we can store latency statistics. If we set a requirement for 100ms on the 90th percentile and 200ms for the 100th percentile, we can compare measurements and application requirements directly. Or, as Meta puts it: “correlate the relationship between network quality of service metrics with user quality of experience metrics.
Now that we have a robust method for determining if the network is good enough, we should go from the correlation, back to our medical diagnosis example, to provide relatable statements for the end user. By also having application developers (or SLA makers) formulate a “beyond this point, my application has 0% chance of being functional”. We can get somewhere.
By having applications formulating this, we have:
If the network quality is X or better, the application will work perfectly
If the network quality is below Y, the application will not work at all
The mathematical Distance between the two
The 3rd point is crucial, because internet experience is not binary (it works or it doesn't). There is plenty of nuance in between. Having a distance measure gives us the ability to normalize and make statements like:
“Application X (e.g., Zoom) has a 75% chance of working perfectly on this network”, which is pretty relatable.
Principle 5: We need to be able to figure out the cause of degradation
When dealing with latency as a network quality metric, one difficulty is that latency may have several sources. Let’s remind ourselves of some cor e principles. To make a network quality metric actionable, we need ways of separating the causes: To figure out how to fix something, we first need to know what is broken.
There are 3 main causes of latency:
Physical Travel Time, which is governed by the speed of light and network technologies
Serialization, which is the processing time of packets
Queuing, which is caused by competition with other traffic.
However, #2 above is becoming negligible in a modern network, and certainly for any network capable of a metaverse-esque application. So, we are down to Travel Time and Queuing. When observing a network segment over time, we can with simple statistics separate the latency from each cause when using the concept of Quality Attenuation.
Summary
We need a network quality metric that can translate complex network statistics into relatable and actionable statements and be decoupled from network technology and layer.
The network quality metric must be a latency distribution as it is independent of network technology and layer, and lets us compose and decompose network segments and separate root causes which is key for actionability. A latency distribution lets us use common statistical tools, which is necessary as we cannot capture all data about a network, and we have to work in the realm of probabilities.
To make the metric translatable to relatable statements about experiences, the framework needs to let applications or other QoS requirements speak the same language. It has to be something similar to a latency distribution, and use this to translate the network quality into probabilistic statements about application’s performance. E.g., Zoom has a 97% chance of a perfect experience across this network
Luckily, all of this is covered by Broadband Forums standard QED (TR.452)
Appendix 0 - Comparing with other Frameworks:
Comparing with other network quality frameworks:
Appendix 1 - Typical Criticism:
Justification for Quantitative Timeliness Agreements (QTA) as QoS Requirements framework
First, let me succinctly describe my goal: A framework, that with a minimal amount of data and overhead, can translate Applications Network Requirements and any Networks Performance to objective and relatable Application Performance Statements.
Now, QED and QTAs answer my goal. Let me explain how.
We can describe an Applications Network Requirements (APR) as a list of latency requirement percentiles: For example: “Zoom needs: 90% of packets needs to arrive within 100ms, 99% within 200ms, and 100% within 250ms.” and: “Beyond 100 area outside the QTA, there is no chance of the application working”
A latency distribution can be captured and approximated on any network with a range of different techniques.
We can map the APR and the empirically measured latency distribution. If there is a breach we have a mathematical distance between “No chance of working” and “will work perfectly”. We can normalize this into a probability measure.
We have a one-dimensional measure for between perfect and useless. Which makes optimization much easier and the measure easier to understand
For example, it would generate a statement like: “On this network, Zoom has a 94% probability of perfection”
All in all, it requires minimal data, is objective, and can capture a wide range of application requirements and translate it to relatable statements.
Typical Criticism:
Missing Temporal Information in Distributions
A latency series of:
1,20,1,20,1,20,1,20,1,20
and
1,1,1,1,1,20,20,20,20,20
Will have identical distributions, but may have different application performance. We are getting into the tradeoff between ease. I.e. The QTA framework cannot capture all varieties of application outcome.
My answer to this is twofold:
First, we cannot capture latency on every packet that is sent. We can probe and sample, but there will always be unknowns. We are now in the realm of probability. Perfection is impossible, but instead of denying this, I think we should embrace it, which is why I think talking about the probability of outcomes is the way forward. A huge advantage of the QTA framework is having a single distance measure between perfect and useless as it lets us approximate probabilities in between. I do not see how we can create a single distance measure if we add a temporal dimension as well. Another dimension brings us back to (one of the) problems with Mbps, Average Latency, Jitter, and Packet Loss or the challenge of having multiple dimensions of network quality to deal with.
My second point is that adding temporal information still does not guarantee perfection. You could add something like a Pairwise Distance (PWD) measure:
1,20,1,20,1,20,1,20,1,20 ~PWD = 19+19+19+19+19+19 = 171
and
1,1,1,1,1,20,20,20,20,20 ~0+0+0+0+0+19+0+0+0+0+0 = 19
Which would capture the difference.
My aversion to this is that it starts to become very difficult to describe the requirements. Also, because there are many different ways we can get to the same PWD, and there is no guarantee that an identical PWD will have identical application outcomes. It seems to me to add more problems than it solves.
To Conclude, while the assumption of linear relationship between quality and the distance measure will be incorrect many cases, it seems that there is no other feasible solution.